
浅谈文件系统
For most users,the file system is the most visible aspectof an operating system.
It provides the mechanism for on-line storage of and
access to both data and programs of the operating
system and all the users of the computer system.
— Operating System Concept
本文还可以在Notion在线阅读🔗Link
文件系统本质上是一组数据结构,文件系统作为操作系统的一部分,承载着上层应用和底层储存设备的数据传输。
最近在折腾使用的ZFS作为默认文件系统的trunas scale,借此契机研究一下文件系统。
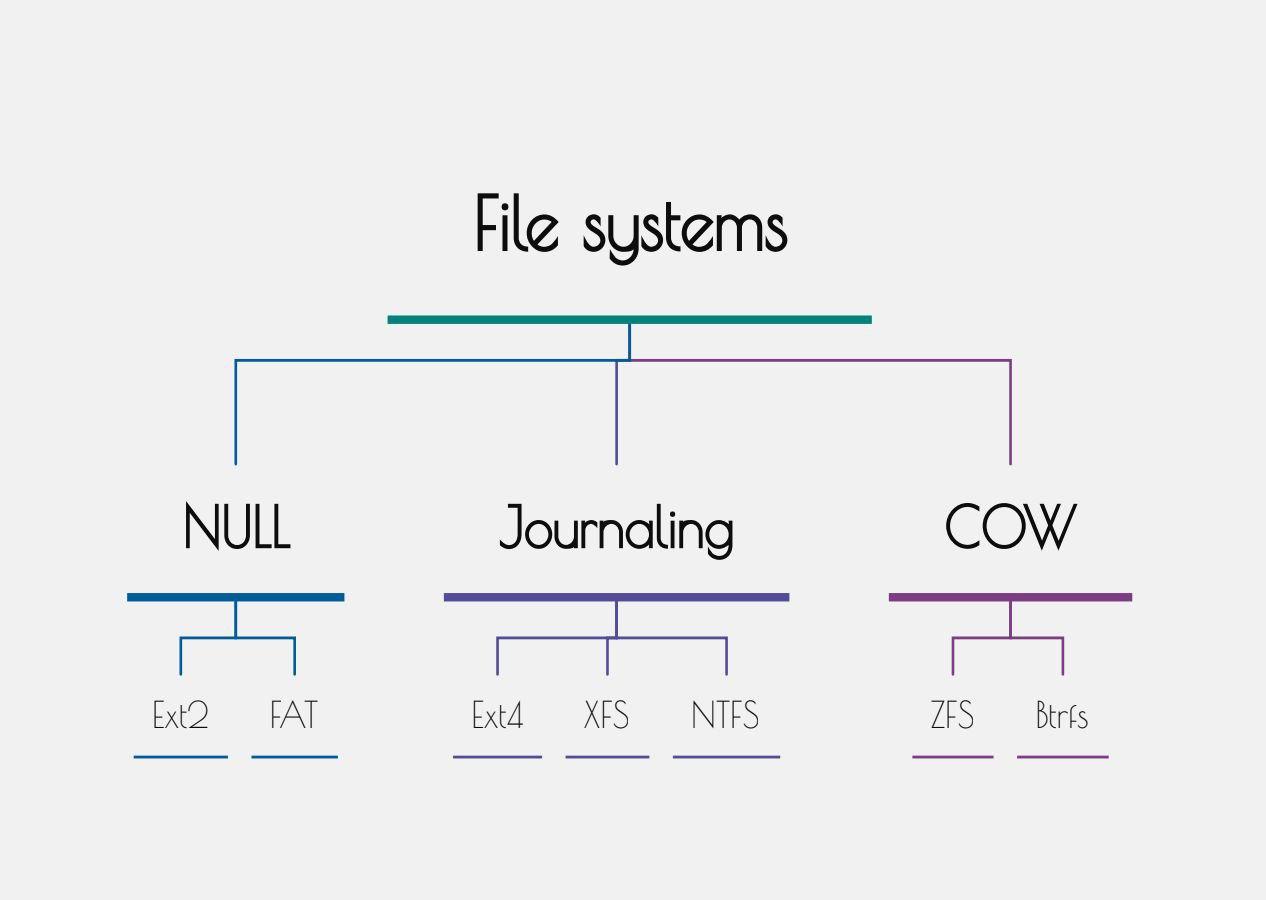
本文将会讲述几种较为流行/有特色的文件系统的特点,以及文件系统的工作原理的一部分(主要是ext4)。文章的最后还会简单的讲讲文件系统的创建和使用。
Ext 1-4
Ext (Extended file system)
linux最初使用minix file system,这个文件系统有许多局限,例如分区大小不能超过64MiB,文件名长度不能超过14个字符。
开发者Rémy Card为了解决这些不足,设计了ext文件系统。
ext是首个专为linux内核开发的文件系统,也是首个使用VFS API的文件系统,在1992年4月发表
ext最大可以存放2GiB大小的数据,文件名最大长度也增加到了255个字符。
Ext2
但Ext文件系统依然有许多限制,例如inode不变性和碎片化问题,ext的继承者ext2,同样由Rémy Card设计,在1993年1月发布。
相比前辈ext,ext2最大文件大小拓展至2TiB,最大卷容量在后期达到32TiB。
ext2取得了相当大的成功,使得minix file system在linux使用者中逐渐变得无人问津。
ext2在当时成为了许多linux发行版的默认文件系统,例如Debian。
实际上ext2直到现在仍在被使用,例如u盘和引导分区中,Ext2并不是一个日志文件系统,但也因此有着更优的性能和更少的读写量(闪存存储器的寿命是有限的)。
Ext3
ext3在2001年11月发布,由Stephen Tweedie等人开发。
ext2被诟病的一点是容易因为断电或者计算机故障而被损坏,ext3相比ext2最大的改进在于引入了journaling(日志),日志的存在为文件系统增加了一层额外的保护。
Ext4
时间来到2006年6月,ext3的维护者曹子德先生(Theodore Ts’o)宣布了ext4项目的开发计划,在Linux开发人员的努力下,ext4在2008年10月正式获得了Linux内核的官方支持。
ext4对于ext3相比ext3对于ext2有着更大的提升,ext4引入了ext3所缺乏的许多功能。
ext4现在已经非常成熟,是现在大多流行linux发行版的默认文件系统。
特点
日志(Journal)
日志是为了增强文件系统安全性的一种措施,在数据写入数据到磁盘前先写入日志(临时文件),在文件写入到磁盘完成后再删除日志,这样就可以在数据在因为断电等因素受到损坏时通过读取日志来进行补救。
日志的本质也是文件,所以也会受损,所以ext4在ext3的基础上对日志增加了校验和,进一步增强了文件系统的健壮性。
日志分为几种模式:
- Journal(数据模式):索引节点和文件都会被写入日志;丢失数据风险低,但性能差
- Ordered(顺序模式):只有索引节点数据会被写入日志,在对应的元数据标记为提交前,强制写入文件内容。只有数据成功写入后才删除;在性能和安全性之间取得了良好的折中,这也是大多Linux发行版的默认选项
- Writeback(回写模式)只有索引节点数据会被写入日志,但不控制文件数据何时写入;丢失数据风险高,但仍比不用日志好
ext4也因此被称作ext4日志文件系统。
容量
ext4文件系统最大支持16TiB的文件和1EiB的卷大小。
并且不限制子目录的数量。
区段(Extent)
ext4用来取代先前的block mapping所使用的技术,一个区段是指一大段连续的物理区间(最大128MiB),它在索引节点表中只记录刚开始的地址,这样可以增强大文件的读写性能并减少碎片化。
一个inode可以存储4个extent,超过4个的extent会被Htree(一种B树的变种)所存储。
预先分配数据块(Persistent pre-allocation)
为文件提前预留块空间,用0填充这些块以备使用,可以增强数据的连续性,减少碎片化。
ext4还支持其他许多的功能:
- 数据压缩和加密
- 在线磁盘整理
- 更先进的时间戳
- 更多的特性可以参考kernel.org的wiki
原理&内部结构

Superblock
Ext文件系统会将分区的最开始一部分作为superblock,里面存放着文件系统结构并将其定位在物理磁盘上的元数据。superblock会被备份到保留的分区,在superblock损坏时可以用一些工具来恢复(当然,superblock受损的概率很小)。
可以使用dump2fs来读取superblock中的内容:
1 | $ sudo dumpe2fs /dev/nvme0n1p9 | head -10 |
可以看到superblock存储了许多有用的信息,例如文件系统的UUID,支持的功能(has_journal就是支持日志),当前的状态等。
Block Bitmap
用来表示一个数据块是否被占用,1表示已使用,0表示空闲。
inode (index node)
inode table用于存放索引节点,ext文件系统用索引节点来索引文件。

文件系统使用文件的元数据(metadata)来识别文件。
inode存储着文件/目录的元数据,例如时间,大小,拥有者和ACL(文件名由目录存储),每个文件都有唯一的inode编号。
曾经的ext文件系统的inode数量是固定的,因此限制了文件的数量。
获取一个文件的inode编号很简单,使用ls 指定-i选项就可获取文件的inode编号:
1 | $ ls -ailF fragile.flac |
这个790411就是inode编号。
可以使用stat命令来进一步获取文件和文件系统信息:
1 | $ stat fragile.flac |
一个关于inode的实用例子是链接文件:
stat打印出了文件的大小,修改记录,权限等,除此之外还有一项: Links: 1 这个link就是指向这个文件的链接,
链接文件是 Linux 文件系统的一个优势。如需要在系统上维护同一文件的两份或多份副本,除了保存多份单独的物理文件副本之外,还可以采用保存一份物理文件副本和多个虚拟副本的方法。这种虚拟的副本就称为“链接”。链接是目录中指向文件真实位置的占位符。在 Linux 中有两种不同类型的文件链接:
- 符号链接(symbolic link)
- 硬链接(hard link)
“符号链接”就是一个实实在在的文件,它指向存放在虚拟目录结构中某个地方的另一个文件。这两个通过符号链接在一起的文件,彼此的内容并不相同。
“硬链接”会创建独立的虚拟文件,其中包含了原始文件的信息及位置。但是它们从根本上而言是同一个文件。引用硬链接文件等同于引用了源文件。
— ShellTutorial
如果我们再创建一个指向这个文件的硬链接,此时Links 就会变成2:
1 | $ ln fragile.flac link |
一个有意思的地方是刚才创建的硬链接和原本的文件的inode是相同的:
1 | $ ls -ailF link |
这表明这两个文件本质是相同的,它们指向了存储器的同一地址
XFS
基于B+树的日志文件系统,拥有不错的性能表现
由SGI在1993年开始开发,作为自家操作系统IRIX的默认文件系统,实际上他们当时不知道该给这个文件系统取什么名字,所以就叫’X’FS,但是一直到现在还是叫XFS(
XFS在2000年3月以GPL协议发布,之后XFS的Linux实现加入了Linux主线。
RHEL7替换ext使用XFS作为默认文件系统,SUSE使用XFS作为数据分区的默认文件系统。
特点
日志
XFS也是日志文件系统,但是仅使用回写模式,这使XFS的安全性不如ext,但是提升了性能。
容量
XFS是64位的文件系统,最大支持8EiB(实际上是$2^{63}-1$ bytes)的文件系统。
XFS很适合做存放大量文件和大文件的文件系统。
XFS也支持在线磁盘碎片整理和文件系统在线扩容(类似ReiserFS但是只能变大)。
多线程
XFS文件系统内部被分为多个“分配组”,它们是文件系统中的等长线性存储区。每个分配组各自管理自己的inode和剩余空间。文件和文件夹可以跨越分配组。
这使XFS有着很强的并行I/O能力,也让XFS的I/O线程、文件系统带宽、文件大小及文件系统本身有着很强的可伸缩性。
缺点是虽然提升了文件系统性能,但增加了cpu的负担。
Direct I/O
对于高I/O吞吐量的应用,XFS允许数据不经过内核cache直接让I/O操作应用于userspace,降低CPU的负载并尽可能利用磁盘的全部带宽。
Direct I/O同时允许了对一个文件的并行写入。
确定速率I/O (Guaranteed-rate I/O)
XFS会动态计算磁盘的可用I/O性能,并保留一定的带宽给文件系统使用来保证系统性能。
其他特性例如快照可以参考XFS社区wiki和wikipedia
NTFS
巨硬家的日志文件系统,在windows上作为默认文件系统。
开摆!.md
FAT - ExFAT
也是巨硬家的文件系统,但是没有日志,现在移动设备用的比较多。
开摆!.md
ZFS
ZFS即Zettabyte File System,强大的写时复制文件系统,也是卷管理工具
ZFS最早由sun公司为自家的Solaris操作系统开发,ZFS原本是闭源的,2005年ZFS随着openSolaris项目而开源。后来sun公司被甲骨文收购,现在ZFS属于甲骨文旗下的项目。
其开源实作为OpenZFS,fork自openSolaris。
但是由于开源许可的问题,ZFS在Linux上并不是那么流行。
BSD和Ubuntu server的默认文件系统。
特点
写时复制(copy-on-write,COW)
与日志模式不同,cow提供了另一种保护文件的方式
在cow的模式下,对一个文件进行修改并不会直接修改这个文件,而是将数据放入文件系统的另外一个地方,这样即使写时断电损坏,原有的数据也不会丢失。
相比日志需要在安全性和性能之间做出权衡,cow兼顾了性能和安全性。
cow文件系统日渐流行,ZFS就是其中一种。
容量
假设每秒钟创建1,000个新文件,达到ZFS文件数极限需要大约9,000年。
ZFS的一大特点就是容量非常大。
ZFS是一个128bit的文件系统,可以比64bit的文件系统多$1.84 × 10^{19}$倍的地址数量。
单个文件最大支持16EiB,最大文件系统大小$256*1024^{4}ZiB (2^{128} bytes)$。
(1YiB=1024ZiB,1ZiB=1024EiB, 1EiB=1024PiB,1PiB=1024TiB)
在文件容量方面,ZFS吊打了上述所有文件系统。
存储池
不同于传统的文件系统,ZFS不仅是文件系统,也是卷管理工具,ZFS在存储数据时基于虚拟的储存池(zpool),每个zpool又由若干vdev(虚拟设备)组成。
ZFS有内建的RAID功能(称作RAID-Z),能将多个磁盘组成一个磁盘阵列作为vdev使用。
安全性
ZFS通过很多方面来保证数据安全,除了使用cow和RAID,ZFS还会通过计算校验和,快照和scrub等进一步增强文件系统的稳健性。
ZFS对内存有较高的要求,ZFS“假定”内存是安全,实际上内存也是会出错的,一种解决内存错误的方法是使用ECC内存,此外ZFS的一个缺点是非常消耗内存。
从ZFS的特点可以发现ZFS非常适合做数据的稳定存储,例如数据中心或者NAS。
更多其他的特性可以参考wikipedia以及openZFS wiki
Btrfs
基于B树的高性能的写时复制文件系统
Btrfs是年轻的写时复制文件系统,也是卷管理工具,最初由甲骨文在2007年开始研发,借鉴了Reiser4的许多特性。
Btrfs和ZFS同为cow文件系统,所以有许多相似之处。
Btrfs现在是fedora和SUSE根分区的默认文件系统。
特点
容量
Btrfs也是cow文件系统,但不同于ZFS,Btrfs是64bit的,最文件和大卷大小都是16EiB。
Btrfs同样会把多个磁盘虚拟化为一个存储池,再把存储池分为数个子卷,子卷可以在线调整大小。
快照
Btrfs也支持快照功能,通过快照,可以将文件系统会滚到之前的一个特定时间点,以此来保护数据,并且Btrfs可以对快照加密和设置读写权限。
透明压缩
Btrfs可以在传输数据时进行在线的数据压缩,以此来提供磁盘的利用率,ZFS也有相似的功能。
RAID
Btrfs也支持RAID,现在支持raid0, raid1, raid5, raid6和raid10。
Btrfs作为cow文件系统的新人,基于GPL开源,很多功能还在开发阶段,但是Btrfs有在未来成为Linux的默认文件系统的潜力。
创建&操作文件系统
检测现有文件系统
使用lsblk(list block)命令来列出系统的存储设备,指定-f参数输出文件系统信息:
1 | $ lsblk -f |
FSTYPE(file system type)下面列出的就是文件系统
现在加一块1T大小的硬盘sdb做测试:
1 | $ lsblk -f /dev/sdb |
创建文件系统
建立分区表
一般来说,文件系统都是创建在一个分区里,但也可以直接写进未分区的硬盘
分区并不是本文重点,这里简单写下gpt分区表的创建
使用fdisk命令指定-l参数列出分区表:
1 | $ sudo fdisk -l /dev/sdb |
fdisk没有打印出分区相关信息,说明现在硬盘还未分区。
使用cfdisk可以进行图形化(TUI)的分区操作:
1 | $ sudo cfdisk /dev/sdb |
可以看到硬盘被分为了4个分区,sdb1-3为Linux文件系统分区,sdb4为微软基本数据分区
格式化
构建文件系统即是对硬盘进行高级格式化
使用mkfs(make file system)命令来构建文件系统:
1 | $ sudo mkfs.ext4 /dev/sdb1 #sdb1的1指sdb上的第一个分区 |
ext4文件系统很快就创建好了,使用类似的命令还可以创建更多的文件系统:
- mkefs 创建 ext 文件系统
- mke2fs 创建 ext2 文件系统
- mkfs.ext3 创建 ext3 文件系统
- mkfs.ext4 创建 ext4 文件系统
- mkfs.ntfs 创建 NTFS 文件系统
- mkfs.exfat 创建 ExFAT文件系统
- mkfs.xfs 创建 XFS 文件系统
- mkfs.zfs 创建 ZFS 文件系统
- mkfs.btrfs 创建 Btrfs 文件系统
其他的可以参考这个表格
除了NTFS会执行一遍将硬盘初始化为0的操作而十分费时,其他文件系统的创建基本都是很快的。
用lsblk看一眼,硬盘上已经有了4个文件系统了:
1 | $ lsblk -f /dev/sdb |
MOUNTPOINT 一列还是空的,说明文件系统尚未挂载
挂载/卸载文件系统
挂载文件系统的目的是为了使用文件系统。
使用mount命令挂载文件系统:
1 | $ cd /mnt |
使用df命令可以查看硬盘使用量:
1 | $ sudo df -h |
卸载文件系统可以使用umount命令(比较诡异的是这个就是umount而不是unmount):
1 | $ sudo umount /dev/sdb1 |
删除文件系统
如果想删除文件系统的话可以使用之前的分区工具:
1 | $ sudo cfdisk /dev/sdb |
感谢你能读到文章的最后(如果真的读下来了的话),文件系统十分复杂,笔者的知识有限,发现文章错误的地方欢迎给我留言。
REF
archwiki:
youtube:
Introduction to the Ext4 File System for Linux
4 MAJOR LINUX FILE SYSTEM: EXT4 , XFS, ZFS, BTRFS
bilibili:
wikipedia: